Introduction
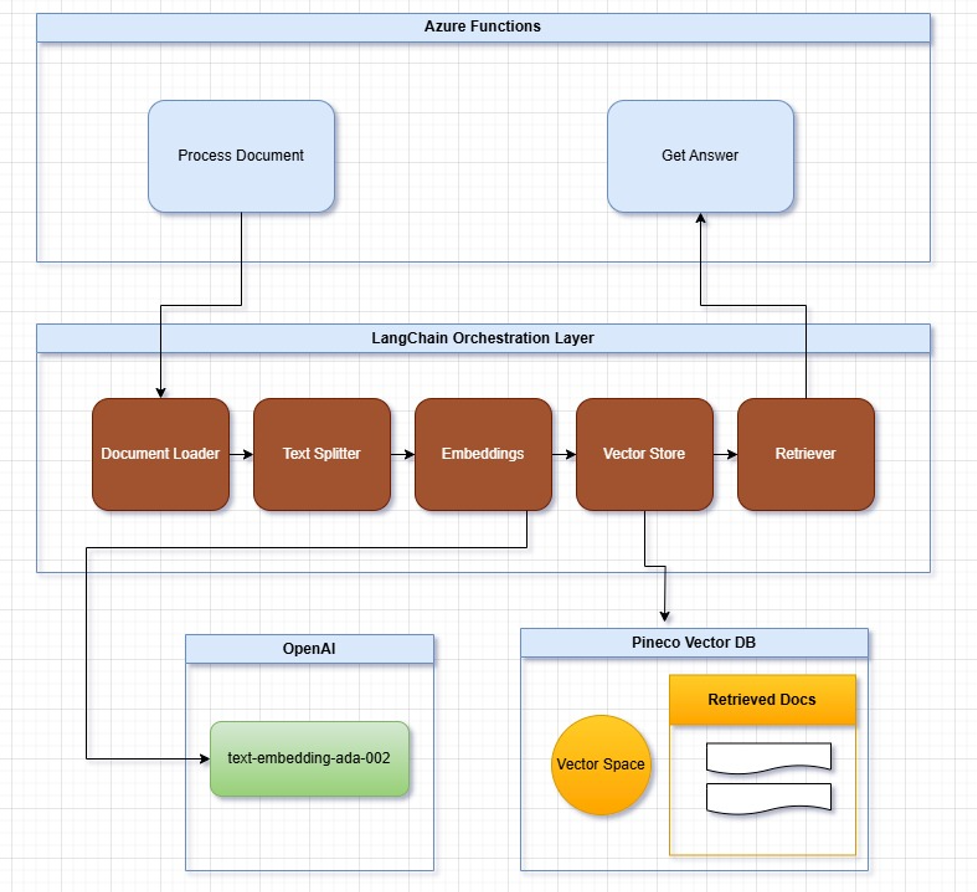
Hello everyone! I’m excited to share my first project working with Python, combining Azure Functions and LangChain to create a scalable chatbot. My aim is to guide you through the process, even if you’re new to Python or serverless architectures. This chatbot can be integrated into various applications, especially Microsoft Dynamics 365 Business Central or .NET solutions, thanks to the modularity and flexibility that Azure Functions provide.
In this post, I’ll cover how I developed the chatbot using Azure Functions, LangChain, OpenAI, and Pinecone as a vector database, highlighting how this architecture simplifies integration across different platforms.
What You’ll Learn in This Guide
This post is designed to walk you through the entire setup and explain the main components in detail, so you can understand why each piece is essential for building an efficient chatbot. Here’s a breakdown of what you’ll find:
- Understanding LangChain – We’ll start with an overview of LangChain and why it’s beneficial for integrating language models like OpenAI’s GPT. This section shows how LangChain simplifies key processes such as text splitting, embedding creation, and document retrieval, which are vital for any chatbot.
- Exploring Retrieval-Augmented Generation (RAG) – To enhance the chatbot’s responses, we use RAG, a technique that improves the accuracy of answers by allowing the model to access external knowledge sources. This section will explain how RAG works and why it’s useful.
- Why Choose LangChain over Traditional RAG – Here, we’ll discuss how LangChain automates many of the manual steps involved in a traditional RAG setup, making it more efficient and flexible. This lets developers focus on the unique features of their applications without being bogged down by infrastructure details.
- Selecting Pinecone for Vector Storage – To handle the high-dimensional data from language models, we need a specialized vector database. Pinecone was chosen for its efficient vector storage, scalability, and accessible free tier. We’ll cover why Pinecone is a great fit for this project, especially in managing embeddings and similarity searches.
Why LangChain? Understanding the Need
LangChain is a powerful framework designed to simplify working with large language models (LLMs), such as OpenAI’s GPT. When building applications with LLMs, you typically face complexities like document handling, embeddings creation, and constructing meaningful responses. LangChain abstracts many of these challenges, providing tools for:
- Automatic Text Splitting: Breaking down large documents into manageable chunks.
- Embeddings Creation: Converting text into vector representations to capture semantic meaning.
- Document Retrieval: Efficiently searching through documents based on vector similarity.
- Prompt Construction: Seamlessly combining user queries with document data for context-aware responses.
The Retrieval-Augmented Generation (RAG) Approach
Retrieval-Augmented Generation (RAG) is a technique that enhances LLM capabilities by supplementing them with external knowledge. Here’s a quick overview of the RAG process:
- Generating Embeddings: Transforming text into vector representations to capture semantic meaning.
- Storing Embeddings: Saving these vectors in a database optimized for similarity search.
- Retrieving Relevant Documents: Finding documents that are semantically similar to the user’s query.
- Generating Responses: Combining the user’s query and retrieved documents to generate context-aware answers.
This approach enables the LLM to access up-to-date, domain-specific information, overcoming limitations like outdated knowledge or hallucinations.
Why Use LangChain Over Traditional RAG Implementations?
While traditional RAG setups require managing each step manually, LangChain automates the process:
- End-to-End Workflow: LangChain handles everything from text splitting to embeddings creation and retrieval, reducing the need for custom code.
- Integrated LLM Interaction: Constructs prompts by blending user queries with retrieved content, making responses more accurate and relevant.
- Flexibility: LangChain is compatible with multiple vector databases and embedding models, giving you options to tailor it to your application’s needs.
With LangChain, you can focus on building your application’s functionality without getting bogged down by infrastructure complexities.
Why Pinecone? Choosing the Right Database for Vector Storage
When building applications that leverage large language models and embeddings, having a database optimized for vector storage and similarity searches is crucial. For this project, I selected Pinecone as the vector database. Pinecone is specifically designed to handle high-dimensional vectors, which makes it ideal for applications that require efficient and scalable similarity search functionalities.
Key Benefits of Pinecone for this Project
- Optimized for Vector Data: Unlike traditional databases, Pinecone is built to store and index embeddings—high-dimensional vector representations of text. This allows for quick and accurate similarity searches, which is essential for retrieving relevant documents in applications like chatbots or recommendation engines.
- Fully Managed Infrastructure: Pinecone offers a fully managed, serverless infrastructure that can automatically scale as your application grows. This scalability is especially beneficial in production settings, where demand might fluctuate, and managing infrastructure can become a burden.
- Generous Free Tier: Pinecone’s Starter Plan provides a generous free tier, which includes up to 1GB of vector storage and allows for the processing of 2 million write and 1 million read units per month. This makes it an ideal choice for developers and small applications looking to experiment and build without incurring initial costs.
- Easy Integration with LangChain and OpenAI: Pinecone integrates seamlessly with LangChain, which simplifies the workflow for storing and retrieving embeddings. Additionally, with support for APIs, it’s easy to set up and query from within Azure Functions, making the whole pipeline—embedding creation, storage, and retrieval—efficient and manageable.
- Flexibility for Future Scaling: As your application needs evolve, Pinecone offers flexible paid plans that can scale with your project. You can choose the cloud provider and region, access robust support, and manage multiple projects with enhanced permissions (RBAC) and advanced indexing features.
Below is an example of how Pinecone’s console configuration might look, allowing you to manage vector storage, namespaces, and index settings effectively.
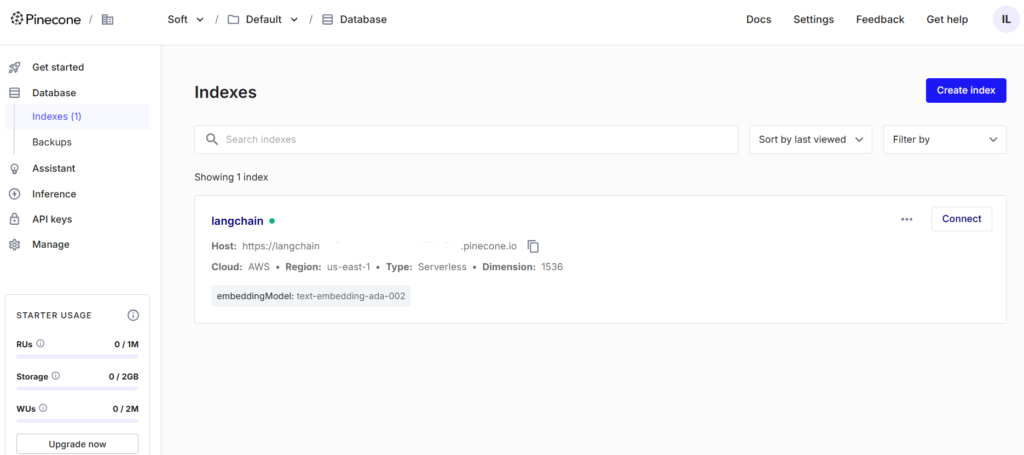
Pinecone Plan Overview
| Plan | Features | Cost |
|---|---|---|
| Starter | 1GB storage, 2M write units, 1M read units per month, community support | Free |
| Standard | Unlimited usage, backups, Prometheus metrics, multiple projects, enhanced support | Pay as you go |
| Enterprise | 99.95% uptime SLA, single sign-on, private link, comprehensive support | Custom pricing |
For more detailed pricing and feature breakdowns, visit Pinecone’s Pricing Page.
By selecting Pinecone, this project benefits from efficient, scalable, and manageable vector storage without upfront costs, making it accessible for developers and businesses alike to explore powerful machine learning applications.
Setting Up the Azure Function
Let’s dive into creating the Azure Functions needed for our chatbot. Here’s a breakdown of the key steps:
Prerequisites
To follow along, make sure you have:
- An Azure account with access to Azure Functions.
- Basic Python knowledge.
- API keys for OpenAI and Pinecone.
- Access to the GitHub repository: LangChainBot.
Step 1: Initialize the Azure Functions Project
Begin by creating a new Azure Functions project using the Python runtime:
func init LangChainBot --python
cd LangChainBot
func new --name process_document --template "HTTP trigger"
func new --name get_answer --template "HTTP trigger"Step 2: Configure Environment Variables
Create a local.settings.json file to store your environment variables securely:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsFeatureFlags": "EnableWorkerIndexing",
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python",
"OPENAI_API_KEY": "your_openai_api_key",
"PINECONE_API_KEY": "your_pinecone_api_key",
"PINECONE_ENVIRONMENT": "your_pinecone_environment"
}
}Important Note: Keep your API keys secure, and never expose them in public repositories.
Step 3: Install Required Libraries
Add the following to your requirements.txt file:
azure-functions
langchain>=0.0.278
langchain-openai>=0.0.2
langchain-community>=0.0.2
openai==0.28.1
tiktoken==0.4.0
python-multipart==0.0.6
numpy>=1.22.0
pinecone-client>=2.2.1Install dependencies with:
pip install -r requirements.txtImplementing the Azure Functions
Here’s the core of the chatbot functionality:
The process_document Function
This function handles document processing, including splitting, embedding, and indexing content in Pinecone.
The get_answer Function
This function retrieves relevant documents, builds a context, and generates an answer.
Testing the Application
Testing is crucial to ensure your application works as expected.
Using Postman
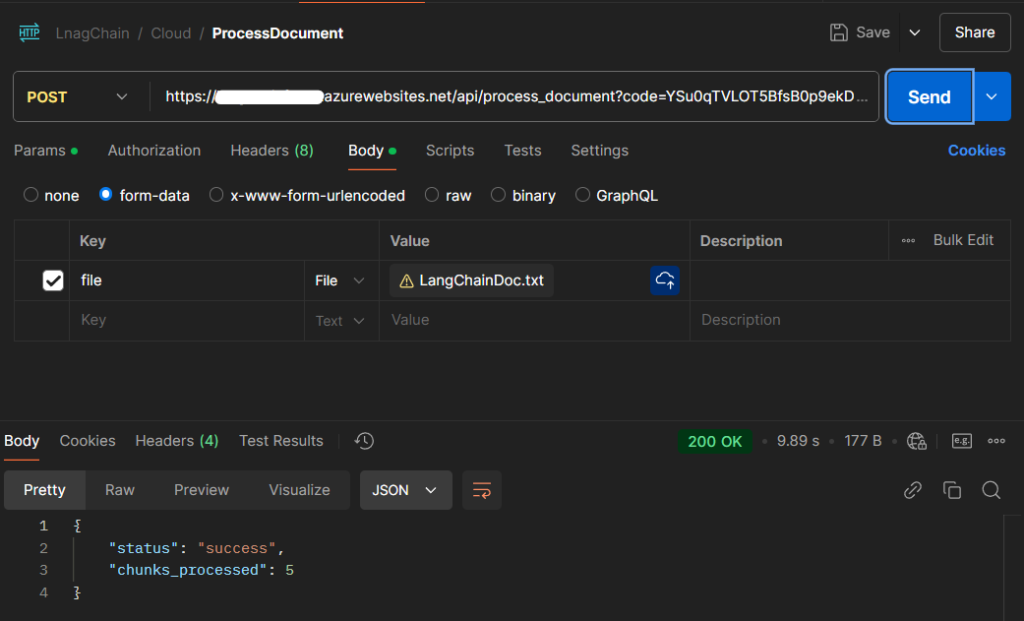
- Process Document Endpoint:
- Method:
POST - URL:
http://localhost:7071/api/process_document - Body: Raw text document content.
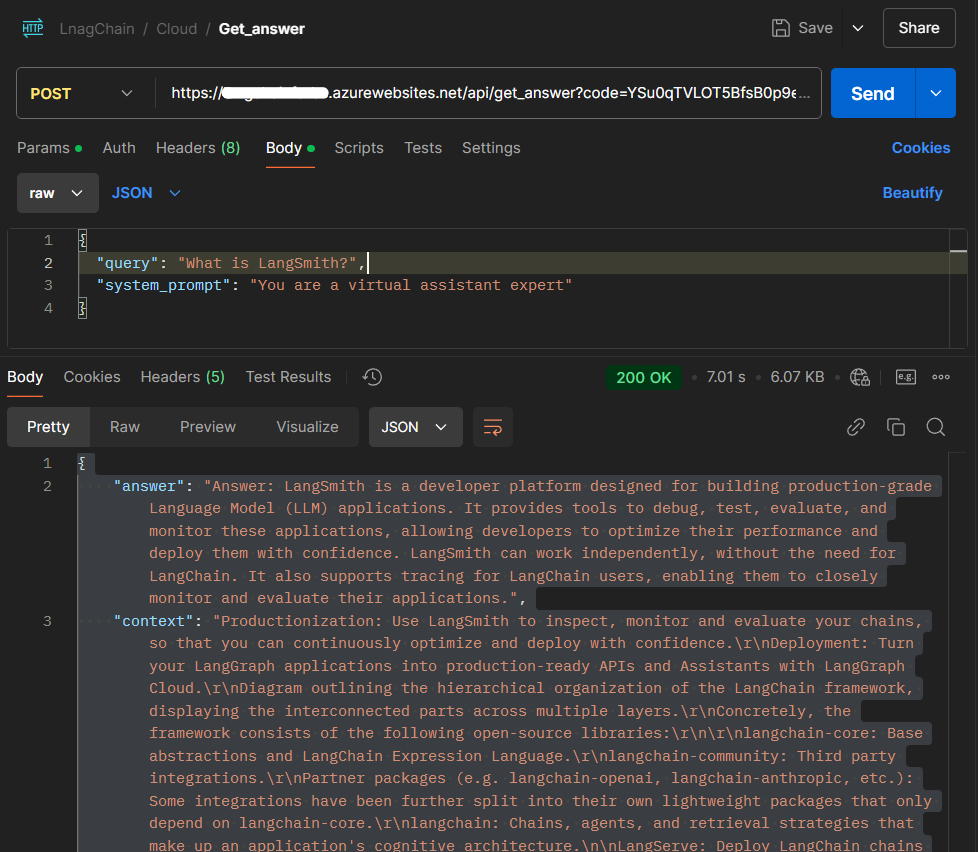
- Get Answer Endpoint:
- Method:
POST - URL:
http://localhost:7071/api/get_answer - Body (JSON):
{ "query": "What is LangChain?" }
Conclusion
By using Azure Functions and LangChain, this project demonstrates how to build a scalable, serverless chatbot that integrates advanced language models seamlessly. LangChain simplifies each step in the Retrieval-Augmented Generation (RAG) workflow, from handling documents to creating embeddings and constructing prompts. This setup forms a robust foundation that’s compatible with a variety of platforms, allowing developers to focus on adding unique value to their applications rather than dealing with complex infrastructure.
One key aspect of this architecture is the use of embeddings—a dense and meaningful representation of the semantic meaning of text. Each embedding is a vector that reflects the semantic similarity between texts, which powers vector similarity searches. This type of search is crucial for retrieval systems and can be supported by databases optimized for handling vector data. While Pinecone is used in this project for its efficient and scalable vector storage, other databases are also compatible. For example, Azure offers several robust alternatives like Azure AI Search, Azure Cosmos DB for MongoDB vCore, Azure SQL Database, and Azure Database for PostgreSQL – Flexible Server—all of which can support embeddings for similarity searches, making this solution flexible and adaptable to various needs and environments.
I hope this project provides valuable insights and inspires others to explore the powerful combination of Azure Functions and LangChain. For those interested in diving deeper, all code is available on my GitHub repository. Feel free to review, contribute, or use it as a starting point for your own projects.
You can find the complete code and instructions here: GitHub Repository: LangChainBot.
For additional resources, check out:
- LangChain Documentation
- Pinecone Documentation
- Azure Functions Python Developer Guide
- OpenAI API Documentation
- Understanding Embeddings in Azure OpenAI Service
- Retrieval-Augmented Generation (RAG) Explained